Most AI vendors promise a “plug‑and‑play” LLM that will instantly supercharge any product, yet the reality is a cascade of brittle integrations, hidden latency, and costly failures. At 42 Robots AI we built our business on the opposite premise: LLM integration services are only valuable when they sit behind deterministic, production‑grade code that enforces contracts, validates inputs, and isolates risk. A CTO who has watched shiny demos dissolve into maintenance nightmares will recognize the tension—raw language models are powerful, but they become liabilities without a disciplined integration layer. Our approach is simple: write the core logic first, then invoke the LLM only where it delivers measurable, domain‑specific insight. This deterministic‑first, LLM‑second strategy is what separates sustainable AI from hype‑driven projects.
Key Takeaways
- Favor deterministic, rule‑based implementations whenever they can meet the requirement; reserve LLMs for cases where a structured approach fails.
- Invoke LLMs sparingly and only when they deliver a measurable advantage, treating them as auxiliary tools rather than the core engine.
- Decompose complex problems into small, well‑defined components with strict input validation and explicit output schemas to keep LLM interactions predictable.
- Continuously monitor quantitative metrics—throughput, error rates, latency, and business‑impact KPIs—rather than relying on flashy demos or anecdotal feedback.
- Align every LLM call with a concrete, pre‑approved success criterion; if the criterion cannot be met, fall back to deterministic code.
Why Most LLM Integration Services Fail Before They Start
Most LLM integration projects fail before a single line of production code gets written — and the reason isn't the model. It's the setup.
Most LLM integration services skip the hard prerequisite work: your data isn't clean, your success metrics aren't defined, and nobody's scoped what "working" actually means. You end up with a demo that impresses stakeholders and collapses under real operational load.
That's the core problem with generic LLM consulting — it optimizes for impressions, not outcomes.
Custom AI Development requires the opposite approach: define measurable objectives first, audit your data pipelines second, and only then decide where an LLM adds genuine value.
Skip those steps, and you're not building a system. You're building a liability.
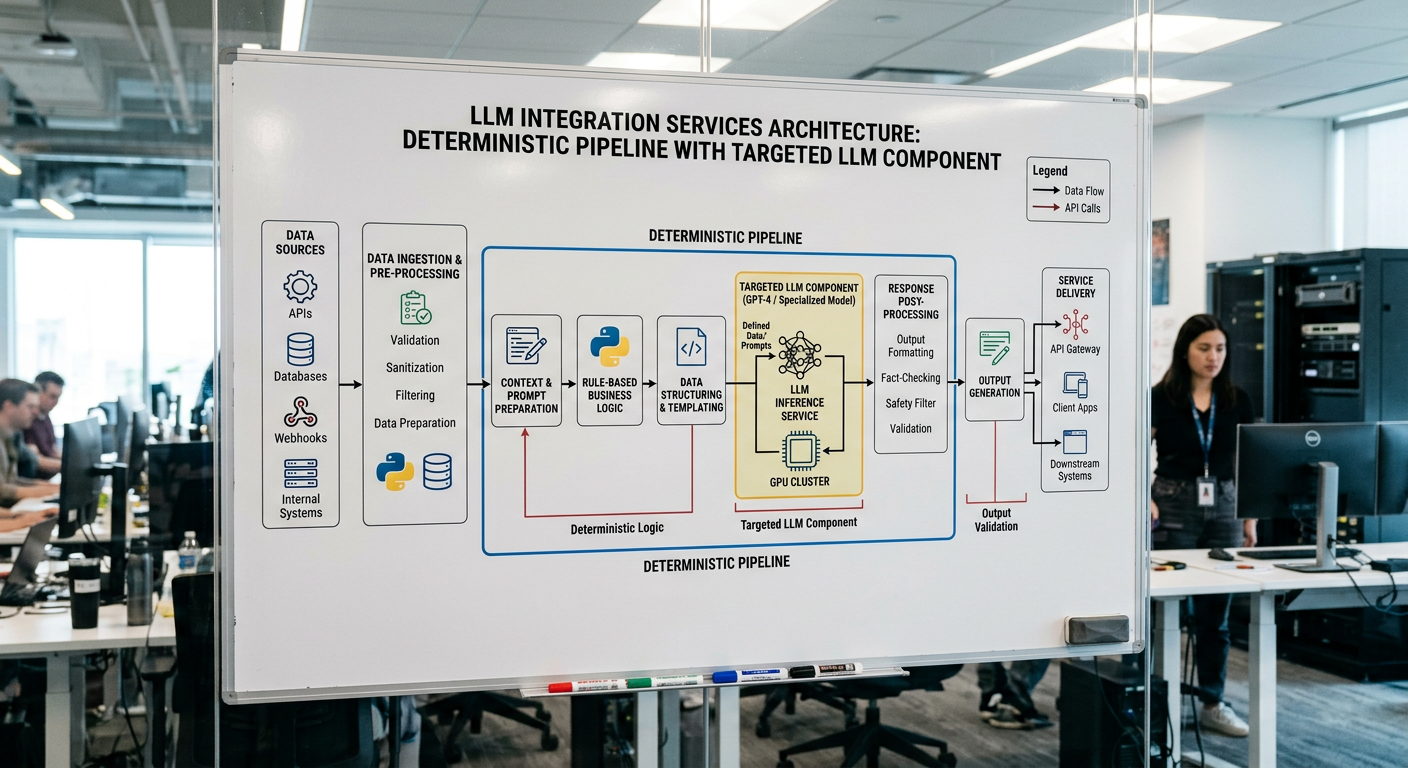
Our Deterministic-First Approach to LLM Integration
Everything that follows in our process — the deterministic-first architecture, the targeted LLM calls, the production-grade monitoring — flows directly from that premise.
Most LLM integration services stumble because they treat AI as a universal drop‑in, ignoring the cost and unpredictability of uncontrolled generation.
The deterministic‑first approach counters this by anchoring every solution in rule‑based logic, structured queries, and conventional code wherever possible.
When teams deviate from that discipline, they fall into the “LLM on a loop” pattern, which creates cascading latency, flaky outputs, and unmanageable failure modes in production.
A disciplined custom LLM integration therefore consists of a thin, well‑defined AI layer that's invoked only after the deterministic stack has exhausted its capabilities.
What "Deterministic-First" Actually Means in Practice
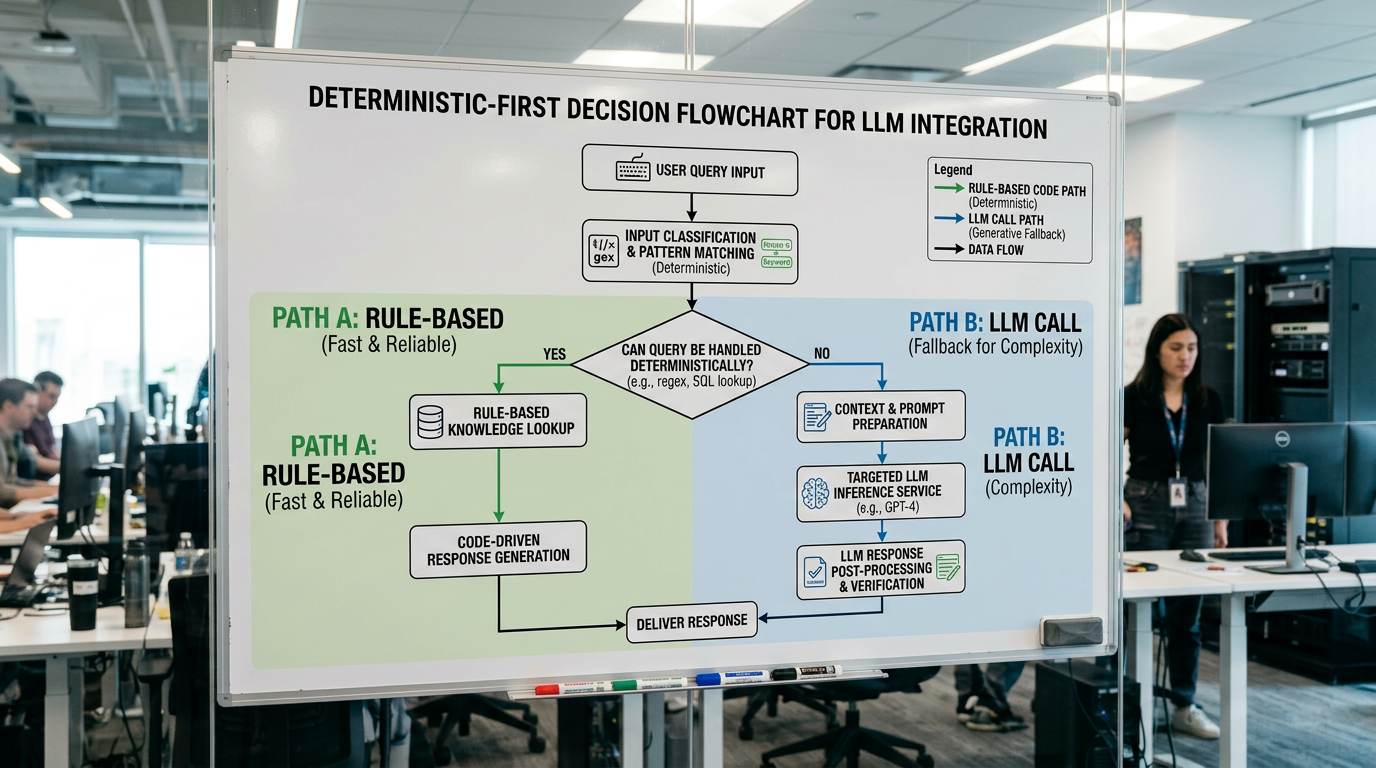
Before an LLM touches a single token of your data, you already know exactly what it is allowed to do — and what it is not. That means defining precise input parameters, explicit rules, and clear boundaries before writing a single prompt. You are not hoping the model figures it out. You are constraining the problem space so the model operates inside a controlled envelope.
In practice, this looks like routing decisions made by deterministic code, validation layers that reject malformed outputs before they propagate, and LLM calls scoped to specific subtasks — not open-ended reasoning chains. You run thoughtful evals continuously. Then you adjust. Trust in LLM-generated results is not assumed — it is earned through repeated, verifiable performance against defined operational goals.
The "LLM on a Loop" Problem and Why It Breaks Production Systems
There's a pattern that shows up constantly in AI system failures: the LLM on a loop. You call the model, feed its output back in, call it again, repeat.
It feels like reasoning. It's actually compounding failure.
That architectural decision is not philosophical — it is what determines whether a system holds up in production or falls apart under load.
The numbers tell the story without needing a study to prove it. Every additional LLM call in a loop inherits the errors of the last. What starts as a workable output degrades fast — and in production, fast degradation means user-facing failures before anyone catches the drift.
The root cause is stochastic behavior plus context drift. Each call inherits the errors of the last.
In multi-agent systems, this compounds further — agents revising outputs based on flawed prior outputs, with no deterministic checkpoint catching the drift.
If your architecture loops an LLM, you've built fragility into the foundation.
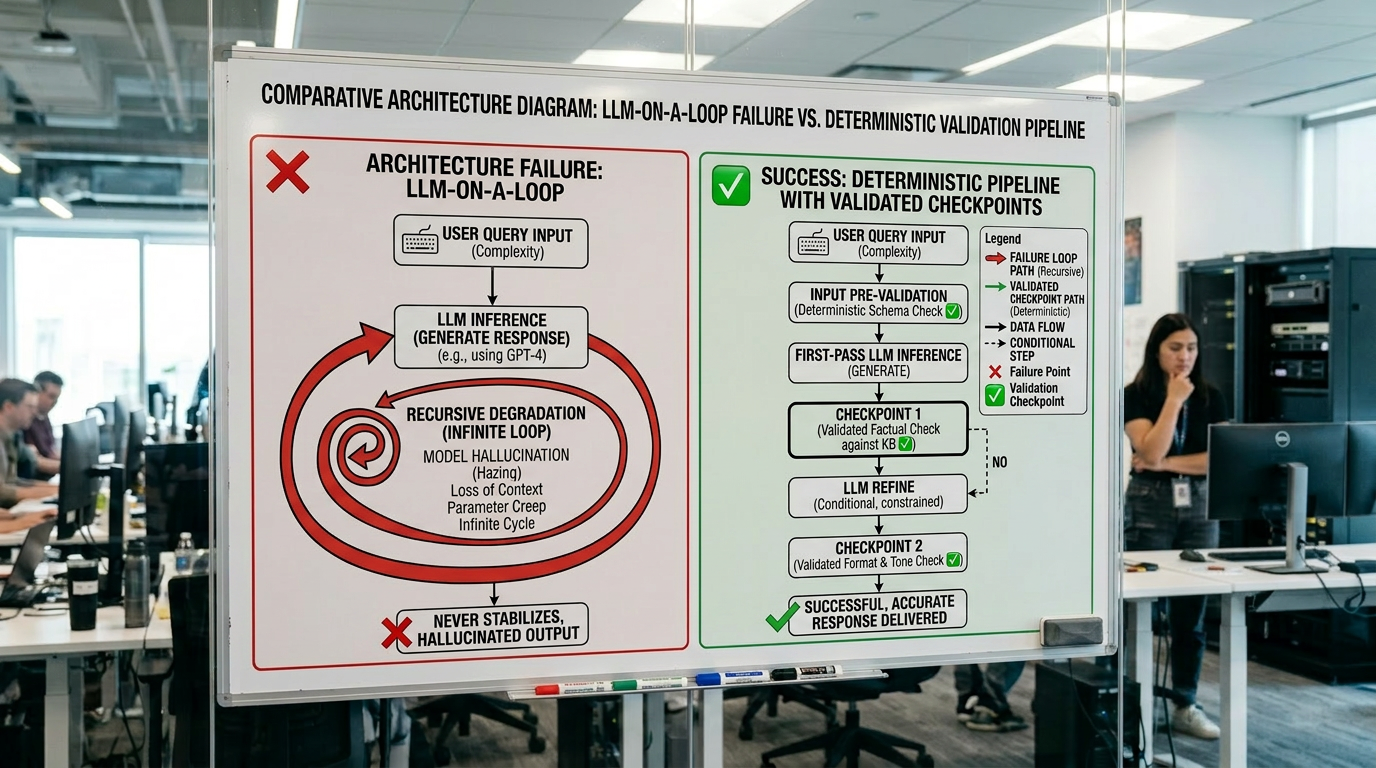
Watch how we break down the LLM-centric trap and why flipping the architecture changes everything:
What Custom LLM Integration Actually Looks Like
Most LLM integration services stumble because they treat the model as a plug‑and‑play component, ignoring the realities of data heterogeneity and system constraints.
A deterministic‑first approach flips that mindset, insisting on predictable preprocessing, schema enforcement, and reproducible inference before any creativity is introduced.
When you then layer a “LLM on a loop” over this foundation, the system becomes brittle: feedback cycles amplify nondeterminism, leading to drift, latency spikes, and hard‑to‑debug failures.
Consequently, a truly robust custom LLM integration is built around disciplined pipelines, strict monitoring, and versioned models—showing that measured, engineering‑driven use of LLMs outperforms throwing AI at every problem.
Custom Data Pipelines Built Around Your Documents
Most LLM integrations fail in production because they treat your data as an afterthought. Your documents aren't generic — they carry specific terminology, formats, and operational context that off-the-shelf pipelines can't handle.
That principle is what drove a 99% automation rate in our healthcare RCM case study — a high-volume document processing system built around deterministic-first pipelines, not a generic LLM wrapper.
Building a pipeline that works means cleaning and structuring your data before it ever reaches the model. That preprocessing step is one of the most effective ways to reduce hallucinations.
From there, you're mapping your proprietary datasets to the model's inputs so outputs actually reflect your workflows, not some averaged approximation of them.
It's iterative. You test, measure output quality, tune the pipeline, and repeat. You also build in Human-in-the-Loop validation checkpoints where accuracy genuinely matters.
The result is a system that understands your documents — not one that guesses at them.
API Integration Without Replacing Your Existing Stack
Ripping out your existing stack to accommodate an LLM is the wrong move — and it's usually unnecessary. Your existing systems already handle orchestration, business logic, and data flow. The LLM doesn't replace that — it plugs into it.
Good API integration means the LLM becomes one node in your existing pipeline, not the pipeline itself. It receives a specific input, returns a specific output, and your deterministic code handles everything around it — validation, routing, error handling, retries, logging.
"We measure results, not impressions." That means no rip-and-replace. Your CRM, ERP, or internal tooling stays intact. You're adding a targeted capability — not rebuilding your architecture around a model with an uncertain shelf life .
Production-Grade Monitoring, Error Handling, and Model Versioning
Deploying an LLM into production without monitoring is the same as shipping software without logging — you won't know it's broken until someone tells you. You need continuous performance tracking against predefined accuracy thresholds, not periodic manual spot-checks.
Error handling means building real fallback mechanisms. When hallucinations occur — and they'll — your system should revert to deterministic alternatives automatically, not surface garbage to users.
Model versioning isn't optional. You maintain detailed iteration logs so you can diff performance across versions, isolate regressions, and debug with actual evidence.
Retraining on curated internal data addresses knowledge drift and domain-specific bias before they compound.
Human-in-the-loop validation closes the feedback loop — user corrections feed directly back into model updates. That's how you build a system that improves instead of decays.
Ready to See This Approach in Action?
What does this approach actually look like when it hits your stack?
It starts with a conversation about your specific problem — not a demo of generic capabilities. 42 Robots AI maps your existing workflows, identifies where deterministic code handles the load, and pinpoints the narrow cases where an LLM call actually earns its place.
You don't get a rip-and-replace proposal. You get targeted LLM integration services: custom data pipelines built around your document types, API connections into your existing systems, and monitoring from day one.
If you're evaluating AI vendors and you're tired of demos that collapse in production, that's exactly the conversation worth having.
Most vendors sell hype, promising AI that "runs everything." 42 Robots AI treats LLMs as precision components — well-defined inputs, clear metrics, and engineered architecture. By embedding them in disciplined pipelines, we eliminate guesswork, cut latency, and reduce costs while boosting reliability. The result is a system that scales predictably, delivers measurable value, and stays under your control.